It seems to work with with my login with the default OSMC skin but my children’s login that uses the Kodi default skin doesn’t scrape, just some server timeout error.
Actually, I narrowed it down to just one TV show they’re having issues with.
https://www.thetvdb.com/series/ducktales-2017
On the hard drive its TV/DuckTales (2017)/Season 1/S01E02.mkv
I can’t name it anymore straight forward than that but I think it has something to do with the naming some how.
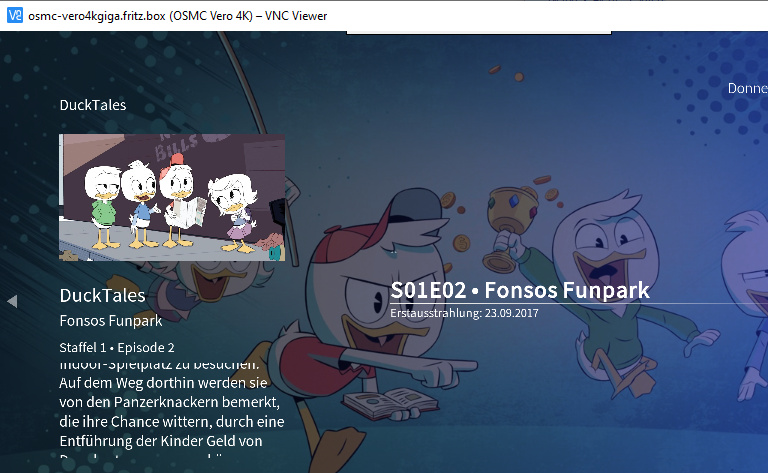
Tried your naming and it worked at once. So, either this was a temporary issue at thetvdb.com or something with your settings?
I suggest to checkt the content settings for “TV”.
Get the same issue 12h ago, not tested again so far. The access to TVDB was problematic for the show “the outsider”. A manual update provides the name to search interface and even “outsi” didn’t returns anything. Searching on the TVDB website returns many result
Site disturbance pops out as the first possible issue, I will retry later on
Shameless repost from another thread:
Because I’m having the same problem with the series His Dark Materials despite sticking to Kodi’s naming conventions and other shows scraping fine in the meantime, I blame TVDB. From this post on the Kodi forums it looks like it’s got something to do with a change of their API and a needed adjustment of the scraping addon. The change text of the scraping addon’s version 3.2.4 supports this:
Release Notes
v3.2.4 24 Jan 2020
- Fix for changes in TVDB search API [metadata.tvdb.com] updated to v3.2.4 by olympia · Pull Request #172 · xbmc/repo-scrapers · GitHub
Again? After the mess of their API change from v2 to v3 from last fall?. TVDB really is testing their users’ patience. ![]()
The old .nfo method did the trick. Just solved it by creating a simple text file tvshow.nfo in the series’ folder. The file contains nothing but the URL of the TVDB entry, in this case https://www.thetvdb.com/series/his-dark-materials.
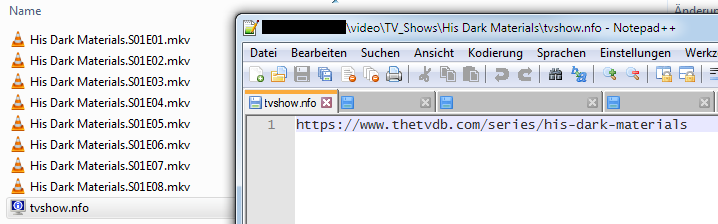
Scraped perfectly on the first try.
The API changes have indeed caused some friction.
Sam
A little off-topic but out of curiosity: Is this the way things are supposed to happen? I’m not involved in any software development at work or leisure time but simply can’t imagine all the services, devices, and websites which rely on TVDB are left to find out about something effectively breaking scraping by, well, the thing not working anymore because they changed something. Were there announcements? An estimated time and date? Is there a mailing list with proposals or staging/beta versions so other developers can adjust their stuff to a change they know will otherwise break things? Is it that unusual to coordinate the release of updates and changes to a site?
My understanding is that the API was known to change well in advance but the new API fell over due to performance problems on the TVDB side
1 Like
I just changed the scraper for the DuckTales (2017) directory to TMDB instead of TVDB as a temporary solution.
And NFO method will always work but didn’t think to try that.
Hope they fix things sooner than later so I don’t have to mess with this with other content in the future.
Another thing that came to mind was that I also have the original DuckTales as well.
But they are in seperate folders as DuckTales and DuckTales (2017) respectively so that really shouldn’t matter but who knows with TVDB.