Have you run this hard drive in another PC for an extended period of time without issue?
Can you try using the Vero 2 without this drive for a while?
Sam
Have you run this hard drive in another PC for an extended period of time without issue?
Can you try using the Vero 2 without this drive for a while?
Sam
No, I haven’t. In fact the original enclosure of the hard drive died some time ago. After that I couldn’t access the hard drive normal way with a file manager. Maybe it messed up some data on the hard drive too. Back then I was able to copy over files with console application testdisk. After that I bought a new enclosure, formatted the whole harddrive, new partition table and copied back the files.
Do you think the harddrive is causing this? Can a harddrive cause this?
I also had some doubts so I ran the command badblocks to see if it’s faulty. Took forever to complete and the result was there are no faulty blocks. Also ran fsck.
When connecting it to a pc I noticed that it takes a few tries, plug/unplug switch on/off until the hard drive gets recognized.
I will try, yes. I also will buy a new enclosure, maybe I got another faulty one…lets hope, would be really uncool if the harddrive is somehow damaged in a way I cant find out…
If your enclosure supports SMART then you can run smartctl on OSMC. Otherwise I suggest to connect it directly to a PC (via SATA) and run smart test on it that’s the only way to know if it is fine
smartctl -H /dev/sda
smartctl 6.4 2014-10-07 r4002 [armv7l-linux-3.10.101-7-osmc] (local build)
Copyright (C) 2002-14, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
Thx for the additional input. I think I also tried this test before. Quick test looks ok, gonna do smartctl -t long now and post the output later, if I may.
Edit:
…Testing has begun.
Please wait 402 minutes for test to complete…![]()
Try also smartctl --all /dev/sda
That will show you errors and other details.
still going at it ? haha this is entertaining if this was my gear i would just scrap it and reinstall but your just trying to push forward 
I have a feeling something’s wrong with my hard drive. But before I toss it out the window with all the data on it I want to be sure 
I read test passed and no errors in log…but I can’t really interpret the middle part:
smartctl --all /dev/sda
smartctl 6.4 2014-10-07 r4002 [armv7l-linux-3.10.101-7-osmc] (local build)
Copyright (C) 2002-14, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Caviar Green (AF, SATA 6Gb/s)
Device Model: WDC WD30EZRX-00D8PB0
Serial Number: WD-WMC4N0DDNZ0S
LU WWN Device Id: 5 0014ee 05931ef2a
Firmware Version: 80.00A80
User Capacity: 3.000.592.982.016 bytes [3,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Wed May 4 20:13:30 2016 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 248) Self-test routine in progress…
80% of test remaining.
Total time to complete Offline
data collection: (40080) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off supp ort.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 402) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x7035) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_ FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 184 180 021 Pre-fail Always - 5766
4 Start_Stop_Count 0x0032 096 096 000 Old_age Always - 4364
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 083 083 000 Old_age Always - 12968
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 683
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 187
193 Load_Cycle_Count 0x0032 170 170 000 Old_age Always - 90152
194 Temperature_Celsius 0x0022 117 099 000 Old_age Always - 33
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 19
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
Looks ok
So ready to scrap that banned addon filled system yet and start clean ?
btw some good reading for ya so that you know what your getting yourself into when installing 3rd party repos
https://kodi.tv/warning-be-aware-what-additional-add-ons-you-install/
http://www.tekto-kodi.com/kodi-news/ares-wizard-steals-your-personal-data/
The results of the long test look the same:
Thanks for the lecture.
Regardless of my fear the hdd is somehow messed up it will be a good idea.
I just had these problems before without any banned addons on kodi.
I bought this intenso hdd cause it was cheap and found there’s a wd green in the enclouse…
I should have switched to a better enclosure right away.
Also had connection problems with this hdd connected to hummingboard, did also get a kernel panic (of which the system could not recover).
WD Green teeeeeh shit !!!
Might be a good idea to replace the disk with a proper disk and do a little spring cleaning on your vero2
Just try using the Vero 2 without this disk. If you don’t get a panic, we can suspect the enclosure or drive.
Ok, I’m using a different hdd now for a couple days and didn’t experience any sad faces or kernel panic screens so I’m marking this thread as solved.
Strange how a broken hdd could do this to a system. I thought this is kind of a binary decision: Hdd works, gets power and is accessible up or hdd doesn’t show and doesn’t work.
I need to revive this thread since I still get kernel panic every now and then.
This last answer from another thread of mine is the assumed cause of the kernel panics:
Yes hdd gets recognized but kernel panics still happen also sad faces in kodi.
It was suggested I simply should reinstall osmc and redo everything.
The reason I don’t want to do this yet is that these sad faces and kernel panics don’t happen in such frequency that one could call the setup as unuseable.
Mabe 3-4 times a month a kernel panic, sad faces maybe a bit more often. After a reboot it’s ok again.
But yeah it’s annoying.
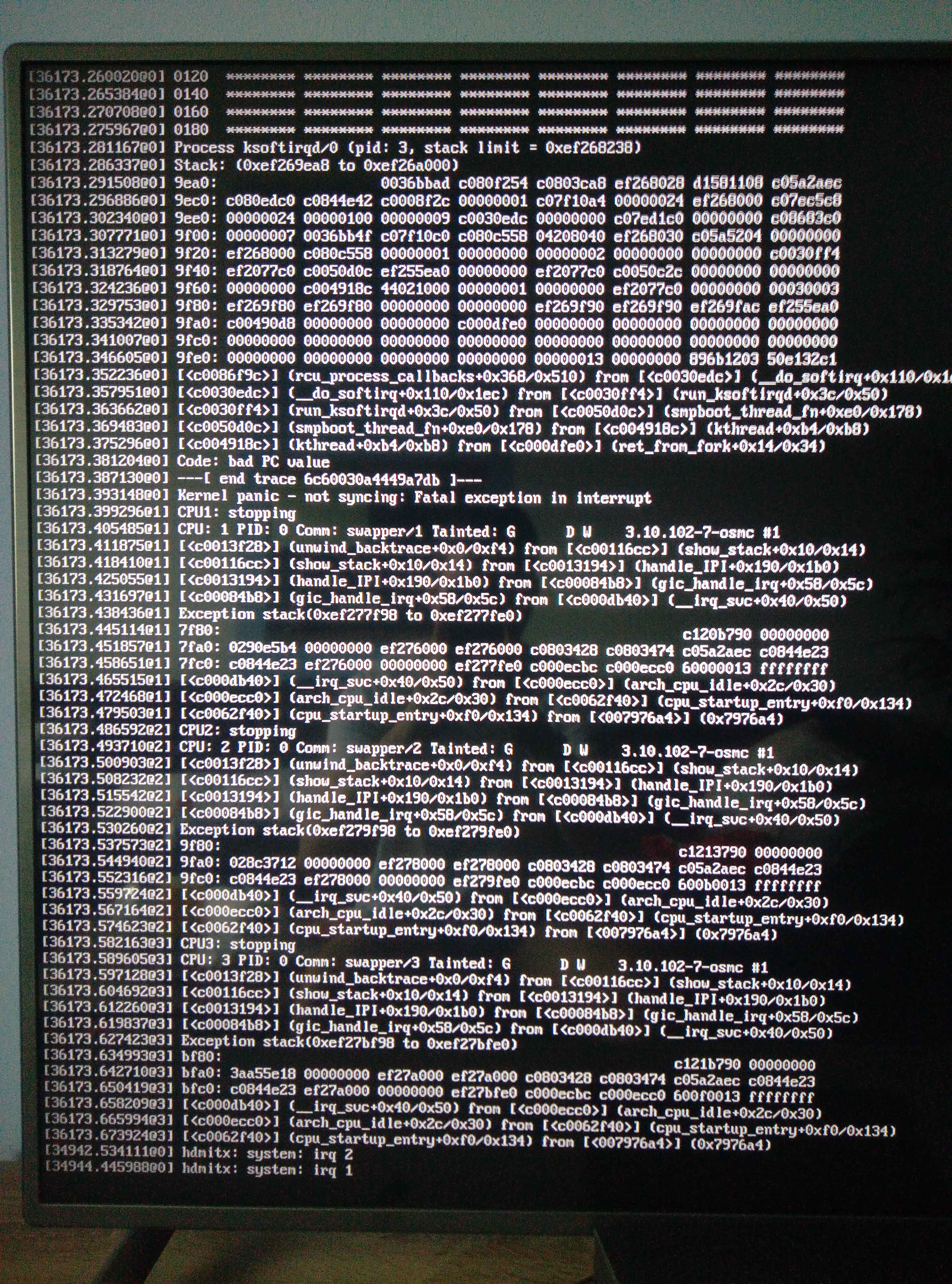
Here are the log and a pic of the recent kernel panic:
http://paste.osmc.io/wolatepizo
My concluding question is: Can I somehow run fsck on the rootfs and try to repair something or is this maybe already done with each boot? Or just for the ext hdd?
A corrupted filesystem shouldn’t cause a kernel panic, unless your rootfs is on it. I don’t remember the specifics here but you may have a bad drive, and I would use smartctl to check that
If OSMC doesn’t panic when the drive is removed, then you have your answer
It does also panic when the drive is removed and I do think the rootfs is messed up somehow
What other applications do you have on your system?
We haven’t seen any other reports of panics, but it’s possible you are tripping up on a bug somewhere. Can you let me know if there’s any form of consistency or a way to reliably reproduce the panic?
Rsnapshot, couchpotato, sickrage, nzbget transmission, openvpn, samba, …thats about it.
Unfortunately it’s not reliably reproduceable.