Yeah, and I’m not “fanning” my drives out either.
I get the same read and write performance on the last drive as I do on the first.
When attached to the Vero’s USB2 I get about 32MBs, when attached to my laptops USB3 I get about 160MBs.
I never have more than one operation running at a time though, that would just be plain crazy.
I’m usually just sending files to the last drive, since the drives before have filled up.
Sometimes I delete stuff and it opens up room on drives lower in the chain.
Not the HDD’s are the issue here. The Path of the data to the HDD is the issue.
And, as soon as a HUB has issues it may slow down the entire serial bus for the other devices.
1 Like
Ah, so your talking about the hub controller failing or something.
You think that’s more likely to happen than a NAS controller?
I really wouldn’t know either way.
It is like with networking.
The slowest link in the path is the speed/quality limiting factor.
The used technology will be what is going to determine the quality of the data delivery.
Every Hop will slow down the interactivity of your connection. Simple fact.
Well, I guess since the Vero is USB2 the USB3 hubs have very little chance of causing a bottle neck.
Here is my speeds of transferring a file from my Win10 laptop to the very last HDD on the chain attached to my Vero 4K+.
This is the path this file has to take:
Laptop > ethernet > gigabit router > ethernet > Vero 4K+ > USB > HDD1 > USB > HDD2 > USB > HDD3 > USB > HDD4
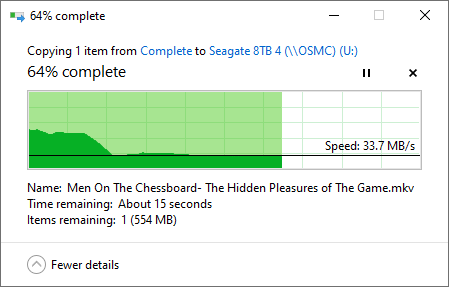
Not too shabby!
The initial burst is cached or something I presume but it flat lines around ~34 MBs.
Right around what i would expect from USB2.
Look, I get it, I’m crazy and my setup is far from orthodox.
I don’t recommend anyone else to do what I do, though I don’t have any issues with it.
But going back to my original concern about why the Vero wouldn’t let me copy or move anything to that drive that had plenty of free space, I’m concluding that something went wrong when I used the Vero’s file manager to transfer a file from one drive to the other and the system flagged it and wouldn’t allow and write operations until it had done a check on the disk.
When I moved the drive off of the Vero and to my laptop, my laptop probably ran that check when it mounted and thus it then allowed me to start writing files to it again.
Does that sound correct?
Would Linux flag a drive and prevent it from being written to until it has checked the drive?
osmc@osmc:~$ df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 774712 0 774712 0% /dev
tmpfs 899232 8780 890452 1% /run
/dev/vero-nand/root 14499760 9846344 3893816 72% /
tmpfs 899232 0 899232 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 899232 0 899232 0% /sys/fs/cgroup
/dev/sda1 7811937256 7663537132 148383740 99% /media/Seagate 8TB 1
/dev/sdb1 7811937256 7795388492 16532380 100% /media/Seagate 8TB 2
/dev/sdc1 7811937256 7811693228 227644 100% /media/Seagate 8TB 3
/dev/sde1 7811937256 6228997064 1582923808 80% /media/Seagate 8TB 4
/dev/sdd1 4882073396 3340268812 1541788200 69% /media/Seagate 5TB
/dev/sdf1 3905450924 3443631588 461802952 89% /media/Seagate 4TB
tmpfs 179844 0 179844 0% /run/user/1000
osmc@osmc:~$ sudo umount /dev/sda1
osmc@osmc:~$ sudo e2fsck -y -f /dev/sda1
e2fsck 1.43.4 (31-Jan-2017)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Seagate_8TB_1: 5316/1907744 files (0.2% non-contiguous), 1916406354/1953506385 blocks
osmc@osmc:~$ sudo umount /dev/sdb1
umount: /media/Seagate 8TB 2: target is busy
(In some cases useful info about processes that
use the device is found by lsof(8) or fuser(1).)
osmc@osmc:~$ sudo umount /dev/sdc1
umount: /media/Seagate 8TB 3: target is busy
(In some cases useful info about processes that
use the device is found by lsof(8) or fuser(1).)
osmc@osmc:~$ sudo umount /dev/sdd1
osmc@osmc:~$ sudo e2fsck -y -f /dev/sdd1
e2fsck 1.43.4 (31-Jan-2017)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Seagate_5TB: 323/1192352 files (0.3% non-contiguous), 835491239/1220942385 blocks
osmc@osmc:~$ sudo umount /dev/sdf1
osmc@osmc:~$ sudo e2fsck -y -f /dev/sdf1
e2fsck 1.43.4 (31-Jan-2017)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Seagate_4TB: 8582/953888 files (1.0% non-contiguous), 861299551/976754385 blocks
osmc@osmc:~$But you do have issues. I pointed out that one of your disks reportedly accumulated 118 errors in the space of 52 hours. That is a big issue. Whether it is a failure of that one disk or a problem with your “unorthodox” set-up is difficult to say. You’d need to be more methodical in your testing to see if it’s isolaed to just one disk.
Clearly, you’re free to use whatever configuration you choose but you must understand that it has the potential to cause corruption on one (or possibly more than one) of your disks. Quoting r/w speeds is not relevant to the discussion since we’re not dealing with a speed problem; this is entirely about firesystem corruption.
I think that you now have enough information to deal with the problem.
1 Like
So my two drives that were the originators of this issue, drive 2 and 3, are refusing to unmount for a fsck.
The Vero is not active so everything should be idle.
Any ideas as to why they are doing this?
Maybe a bad sign of HDDs on their way out?
EDIT: I rebooted the Vero and then I could unmount and check them. All drives still passing checks.
Thanks
Just me 2 cents to this:
-
the topology @Kontrarian uses is supported by the USB 2.0 specs, see USB 2.0 Specification | USB-IF (USB_20.pdf, chapter 4 Architectural Overview)
-
Is it good? No, since
- the number of single points of failure is much higher than a star topology with an 8-port USB 3 hub. Example:
- Star topology, all HDDs connected to an USB hub. What could fail:
- host controller Vero
- cable Vero - hub
- hub
- cable hdd
- hdd
- Kontrarian’s daisy chain topology. What could fail for one of the last hdds in the chain (name it hddX):
- host controller Vero
- cable hdd1
- hub of hdd1
- cable hdd2
- hub of hdd2
- cable hdd3
- hub of hdd3
- cable hdd4
- hub of hdd4
- cable hddX
- hddX
- Star topology, all HDDs connected to an USB hub. What could fail:
- the number of single points of failure is much higher than a star topology with an 8-port USB 3 hub. Example:
-
Is it good? No, since the long path through several USB hubs influences the timing of the USB protocol by every hub means an additional delay in communication. That’s the reason why USB is limited to a max. of 7 tiers. So, the longer the path in the USB component tree, the more likely it is you’re running the protocol to the edge.
What I would do?
- use a star topology with an 8 port USB 3 hub
- use
/etc/fstabmounts and specify to runfsckon problems giving the 6th field infstaba number >1 like
UUID=538214da-b9d1-4460-9e87-de3efcb5da0a /mnt/Intenso2766GB ext4 defaults 0 3
(the UUID of a disk you get with the commandblkid)
The log clearly shows that the mount was done although the file system is not clean; with thefstabsolution thefsckwould have been done
Sep 15 01:34:15 osmc kernel: EXT4-fs (sdc1): warning: mounting fs with errors, running e2fsck is recommended
Sep 15 01:34:15 osmc kernel: EXT4-fs (sdc1): mounted filesystem with ordered data mode. Opts: (null)
-
When using
fstab, the Maximum mount count of the file systems will be evaluated while boot and anfsckwould start while boot even if the file system is clean. You could change that number (default is -1, means no check) like
sudo tun2fs -c 5 /dev/sda1
(on every 5th mount (boot) anfsckwill run on the file system)
Or use the interval-between-checks option to let check the file system wihle boot every 7 days (latest after one week)
sudo tune2fs -i 7 /dev/sda1 -
8 TB hdds are capacity monsters. You need a concept to regulary run a long smart test on each of the hdds and replace such drives immediately once bad sectors can be found.
THIS is now the time where a modern NAS like a Synology e.g. comes into place. These devices “care” about regular maintenance and will do such tests and monitoring for you. If you don’t want to do it regular by yourself usingsmartmontools(which can be somewhat tricky to use), a modern NAS gives you a high degree of convenience plus more safety for your data offering raid technologies.
And a NAS doesn’t use USB/SATA bridges and cables but connects the hard drive as directly as possible ![]()
Thank you very much for your insightful post.
I am definitely going to ditch the daisy chain and “fan” out the drives.
Your suggestion of an 8 port USB hub needs to consider one thing though, any USB hub with more than 4 ports is actually just a daisy chain itself.
An 8 port USB hub would internally be at least two 4 port hubs and maybe even three.
Your point still stands though.
I really like your suggestion on setting it up to run fsck and/or smartmontools automatically .
I’m going to really need to do some reading up on that and I may be picking your brain a little bit about that in the future.
You had mention this once before to me in the past when one of my 2.5" drives was giving me issues: Can't mount previously mounted USB HDD - #106 by JimKnopf
I have been running remote fsck and smartctl checks via ssh from my laptop at the moment and everything looks fine so far with no new errors since my issue when drive 2 was moving a file to drive 3.
The NAS option is expensive, with the NAS itself nearly costing the same as my drives.
I get these 8TB drives for $120 (I have 5 of them at the moment) and a 5 bay NAS cost $600+ typically.
RAID is not a recommended route to go when using “Archive” drives either.
So if I’m getting a non-RAID enclosure to minimize my hubs then a 5 bay USB3 DAS that cost $110 would make more since for my use case I think.
Again, thank you VERY VERY MUCH for your input!
My next step is to fan out these drives instead of the daisy chain.
Then to look into automating checks.
After that I’ll keep my eye open for enclosure options.
Would it make any difference to start the fan with the two separate USB ports on the Vero?
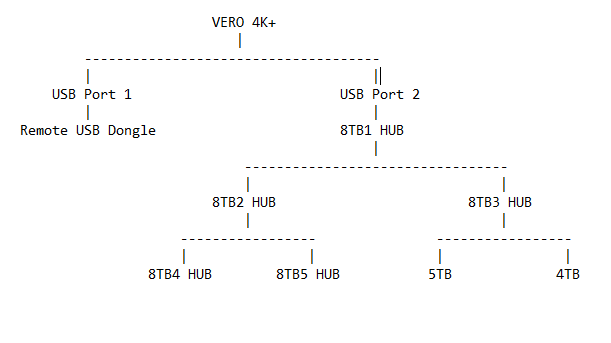
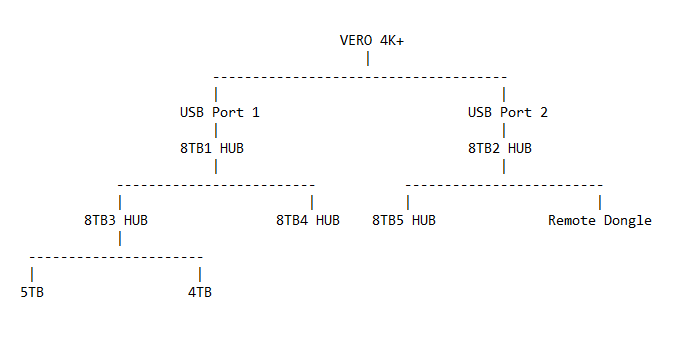
Right now I have 5x 8TB hubs (only using 4 at the moment) and two 2.5" drives (one 5TB and one 4TB) and then there’s the USB remote dongle.
So given this, which would be better?
Option A:
Option B:
This is a simple script I use to collect the status via crontab once a day
1 Like
Awesome!
I will look into that.
I would recommend that you use Option B. Except I’d put the Dongle at the end of the chain as it will use the least bandwidth. So in your chart, I’d swap the last 5TB drive on the port 1 chain with the dongle on the port 2 chain. Or it the 5TB drive also has a hub in it, then maybe put the dongle in that one on port 2 of the chain.
1 Like
It doesn’t have to be expensive. The retail options cost a bit and bring with them a lot of the self management but if you have an old PC about with enough SATA ports (or even buy a PCI SATA controller) it can get much cheaper with options like FreeNAS.
Depending on how advanced your Linux skills are (or you’re prepared to make them) there are plenty of options. In my case I have a Linux box running 6TB drives on 9 or 10 year old hardware doing double duty between NAS (setup with automated SMART testing, push notifications to the phone with disk or RAID issues etc) and a basic desktop. I spent a bit more on PSU and fans but that was personal choice to make it quiet as I use the room for work and the whole lot is crammed in to a case that isn’t particularly conducive to cooling.
The USB3 hub option is cheap and will work (hell, you could even bolt a Raspberry Pi on the front of the hub to act as a NAS and RAID the USB disks if you want but I’m not sure I’d recommend it!) but the flexibility of a NAS device with multiple media clients around the house can’t be beaten.
Using RAID, the NAS devices also do away with the headache of remembering what bit of media is on what drive or what order the drives happened to get picked up in during boot up that could have resulted in the device IDs being different (albeit UUID and the like can work around that).
Only one more point to add: RAID is not infallible and is no substitute for a backup!
Edit: Or you could probably set Linux RAID up on the VERO instead of the RPi - again, I wouldn’t recommend it! Remember OSMC is Linux under the hood so all this automation can be done from there.
So considering my setup and it’s use case I don’t want to have a system wide automated smart test running at certain intervals.
What would be better suited for me is to just ssh in to the Vero and send a command to test a single disk.
This is something I would setup to have done before I go to bed when I know there are no other tasks thet will be required of the Vero that night.
Sending an ssh command to do a smart test isn’t anything complicated, but I do like the script you have that sends an email.
I’m no script wizard (I haven’t written a script since mIRC days) but I would like to ssh in a command to the Vero to do a smart test to a single drive and email me with the results either way good or bad.
Also, I remember in a different thread there being a concern of the drive potentially spinning down in mid test.
What would be the easiest command or script to run to initiate a test for a single drive before I go to I call it a night that would email me the results?
Actually the script I linked doesn’t run any smart test it just checked if smart reports any errors. It actually only will take a few seconds to run.
You can limit it to just specific drive by changing disks="/dev/sda /dev/sdb" to e.g. disks="/dev/sda".
You also could change it to disks=$1 to then start the script with the disk to test as parameter.
To actually initiate a background test of the disk you could just directly start smartctl --test=long /dev/sda against a single disk.